The Arraylake Data Model
This page explains how data are organized in Arraylake.
Overview
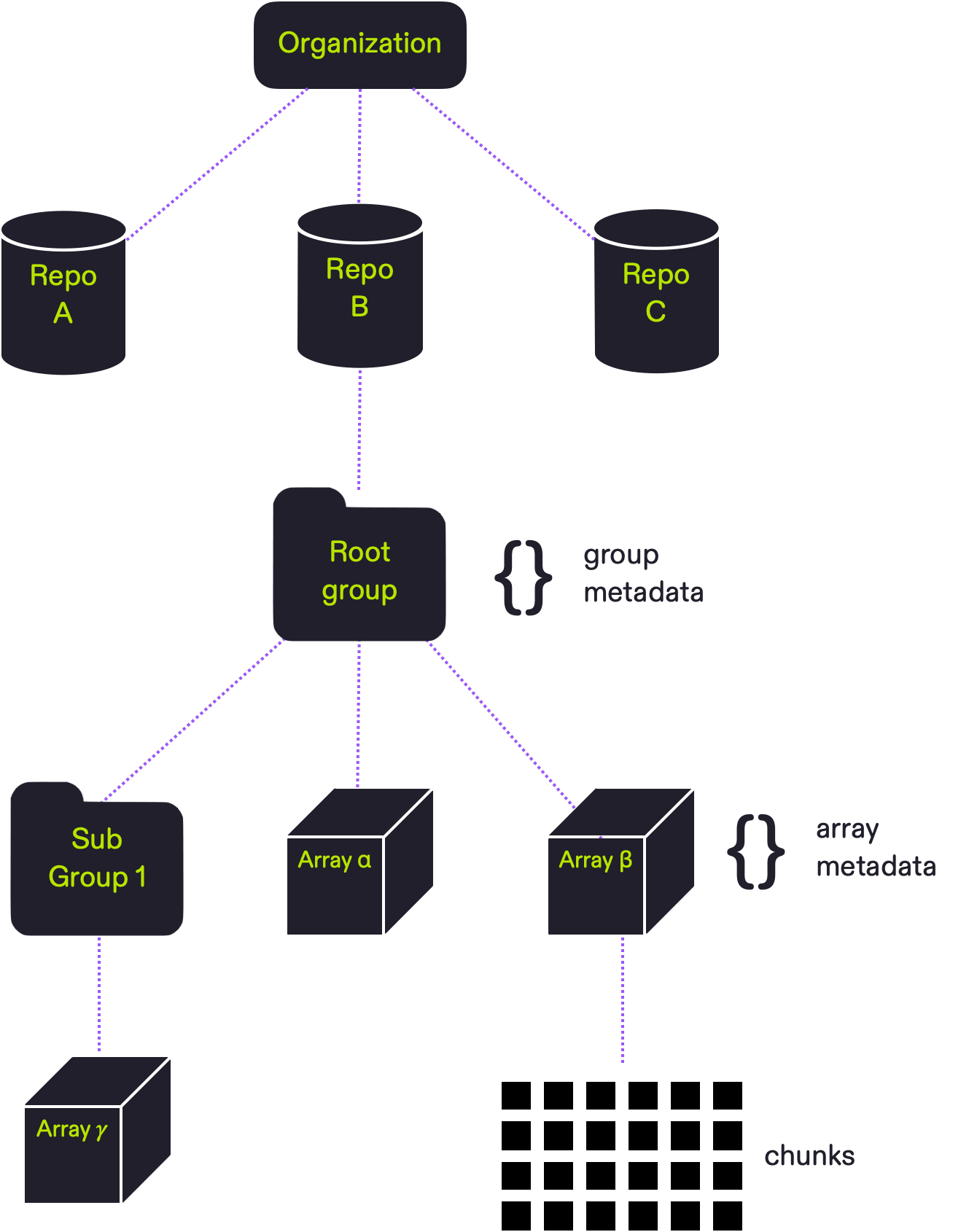
Arraylake organizes data in the following hierarchy.
- An Arraylake organization represents a group of users that owns repos (Repositories).
- A repo (repository) is a hierarchy of arrays and groups that share a single version history and access permissions. Each repo has a root group.
- A group is a container for other groups or arrays.
- An array is a multidimensional numerical array with a specific shape, data type, and chunking scheme.
- User-defined metadata (a.k.a. attributes; key / value pairs) can be attached to any array or group.
Multidimensional Arrays
Multidimensional arrays (henceforth just "arrays") are a foundational data structure for numerical computing, data science, and machine learning. Arrays are containers for numerical data.
Arrays have two fundamental properties:
- shape - a tuple of integers which specify the dimensions of each axis of the array. A 10 x 10 square array would have shape
(10, 10) - data type - a specification of what type of data is found in each element, e.g. integer, float, etc. Different data types have different precision (e.g. 16-bit integer, 64-bit float, etc.)
Every programming language used for numerical computing has APIs for working with for multidimensional arrays. In Python, the following libraries are most frequently used for Array-based numerical computing/
- Numpy
- CuPy - for GPU arrays
- Dask.Array - for larger-than-memory arrays
- Sparse - for sparse arrays
- PyTorch - for deep learning, where Arrays are called tensors
- Jax - another deep learning library
- Xarray - extends the Array data model with dataframe-like concepts, such as dimensions, coordinates, and indexes.
Data stored in Arraylake can easily be loaded into any of these libraries for computation.
Zarr
Arraylake implements the open-source Zarr protocol for storing multidimensional arrays. Zarr prescribes how array data in memory are converted back-and-forth into objects in a storage system. It also provides mechanisms for grouping multiple arrays together into a hierarchy and for storing user-defined metadata together with the these arrays and groups.
A key concept in Zarr is chunks. Zarr partitions arrays into smaller pieces, i.e.~chunks, and each chunk is stored individually in the storage system. A chunk is the minimum unit of data that must be read / written from storage, and thus choices about chunking have strong implications for performance. Zarr leaves this completely up to the user. Chunk shape should be chosen based on the anticipated data access patten for each array.
Zarr supports arbitrary, regularly shaped chunks.
The shape of the chunks is defined by the chunk shape parameter.
For example, for a 3D array of shape (1000, 1000, 1000), there are many different possible chunk shapes.
We like to use food analogies to describe these chunking options:
- 🥟 Ravioli chunks:
(100, 100, 100)- this chunk shape is optimized for isotropic, random access across the whole array. - 🥞 Lasagna / Pancake chunks:
(1, 1000, 1000)- this chunk shape is optimized for reading and writing data in contiguous slices. This is appropriate for 2D spatial data stacked in time when the goal is making maps. - 🍝 Spaghetti chunks:
(1000, 30, 30)- this chunk shape is optimized for extracting long series from a few individual points.
The best way to determine your optimal chunk size is to experiment with a few different options and benchmark against your desired access patterns.
Repositories
The top-level data container in Arraylake is an Icechunk Repository (Repo). A Repo is a hierarchy of Zarr arrays and groups that share a single version history and access permissions. A Repo contains a Zarr root group which can be used as a container for other Zarr arrays or groups.
Commits
A snapshot of the state of a repo is created via a commit. Commits are immutable. Clients can check out a specific commit and are guaranteed to always see the exact same data and metadata. Like with Git, commits only store the diff between the previous version and the new version, allowing repos to be updated incrementally with minimal storage costs. For more details on commits, see the icechunk docs on version control.
Users and Orgs
An ArrayLake Org represents an collection of Users that owns multiple Repos. A company or institution will typically have a single Arraylake organization, and an Arraylake User can belong to one or more organizations.
When using the Arraylake API, the org identifier prefixes a repository name to uniquely identify a repository. For example
my-company/my-repo represents the my-repo Repo belonging to my-company.