Virtual Chunks
Arraylake's native data model is based on Zarr Version 3. However, through Icechunk's support for Virtual Chunks, Arraylake can ingest a wide range of other array formats, including:
- "Native" Zarr Version 2/3
- HDF5
- NetCDF3
- NetCDF4
- GRIB
- TIFF / GeoTIFF / COG (Cloud-Optimized GeoTIFF)
Importantly, these files do not have to be copied in order to be used in Arraylake. If you have existing data in these formats already in the cloud, Arraylake can store an index pointing to the chunks in those files. These are called virtual chunks. They look and feel like regular Icechunk chunks, but the chunk data lives in the original file, rather than inside your Icechunk Repository.
Due to the generality and power of storing pointers to arbitrary data in arbitrary locations in storage, unrestricted access could incur risks, so Arraylake requires a few configuration steps before you can use your virtual chunks. Specifically you will need to set up a Bucket Config, at least one "Virtual Chunk Container", and at least one "Virtual Chunk Access Policy".
Using virtual chunks with Arraylake requires a more recent version of Icechunk: >=v1.1.16, and of the Arraylake client: >=v0.32.0.
When using virtual chunks in Arraylake, there are four relevant concepts:
- Bucket Config - Arraylake configuration for a storage bucket. Typically these buckets contain Icechunk Repository files, but can also contain archival data files.
- Virtual Chunk Reference - Chunk entry in an Icechunk manifest file. Consists of a url to some object (e.g. a netCDF file on S3) plus a byte range start and end.
- Virtual Chunk Container - Icechunk repo config entry, stating that one location is safe to read from.
- Virtual Chunk Access Policy - Arraylake admin-level setting, which permits data in a bucket to be fetched by virtual chunks elsewhere in Arraylake.
Details on how to configure each of these are below.
Bucket Configuration
The original files do not have to live in the same bucket as your Icechunk Repository,
but they must live in a location for which your org has a BucketConfig set up (see Managing Storage).
Simply create a BucketConfig the same way you would for non-virtual data, ensuring that the files you want to reference are within the bucket config's prefix.
HMAC buckets are not supported for use with virtual chunks in arraylake.
If you create an Arraylake repo containing virtual chunks referencing files in a bucket with HMAC authentication method, an error will be raised when you try to authorize access to the virtual chunk data.
Note that you can create BucketConfigs for buckets which you do not have write access to, such as those owned by external institutions (e.g. NOAA NODD buckets).
This means you can ingest read-only references to data provided by other institutions, such as the public sector.
However, Arraylake still requires you to create a bucket config on your own Arraylake organization - users cannot create virtual chunks referencing data in another org's bucket config.
Virtual chunks store explicit paths to locations in storage. Therefore if you move or update the files pointed at by a virtual chunk reference, that virtual chunk will become invalid!
Icechunk can catch this change at read-time (by storing the object's etag and comparing to it's last-modified timestamp), issuing a clear error to any user who attempts to read the stale virtual chunk. But this still means that the repo will appear usable until a user actually tries to read that specific chunk.
This is a fundamental downside of virtual chunks (which are essentially pointers), and means that you should avoid moving, updating or deleting files which you have created virtual references for. If you need to modify the files (or if the files belong to external institution who chooses to modify them) you will unfortunately have to re-ingest by re-creating the virtual references. If you have questions about this limitation please email support.
Authorizing Virtual Chunk Access
For security reasons, Icechunk requires you to explicitly authorize access to virtual chunks. Authorization is required twice, both at write time and at read time. This is good for security, but having to authorize at read time is annoying for repo users, as they need to know about details of a repo before they can open it.
Arraylake provides a similar level of security, but with a seamless experience for repo users. Arraylake does this by still requiring you to authorize twice, but not at repo read time. Instead, Arraylake requires you to authorize:
- Once at the data source, to confirm that the data is safe to be referenced by other repos. This is done by setting a "Virtual Chunk Access Policy", which requires org admin permissions,
- Again on the repo which refers to that data. This is done by setting a "Virtual Chunk Container", which requires repo writer permissions.
Once both these authorization steps are set up, the experience for repo readers reading an Arraylake repo containing virtual chunks is no different from reading a repo that contains only non-virtual chunks.
Since setting a Virtual Chunk Access Policy requires org admin privileges, then regardless of what the non-admin members of your org do, it is impossible for any Arraylake user outside of your org to access any of your org's data via virtual references unless an admin has explicitly allowed this possibility (by setting a public Virtual Chunk Access Policy, see below).
Virtual Chunk Containers
Virtual Chunk Containers are a repo-level setting indicating that the repo contains virtual chunks, and which bucket contains the files referenced by the virtual chunks.
In Arraylake, Virtual Chunk Containers map bucket prefixes containing the data files (such as "s3://my-bucket/someprefix/") to the nicknames of the bucket config for for the bucket containing the files.
They must be set by a user with at least write access to the Arraylake repo.
Arraylake forbids some types of virtual chunk container prefixes which Icechunk supports.
The forbidden prefixes are file:///, memory://, http://, and https://.
If you create an Arraylake repo with a virtual chunk container that uses a forbidden prefix, an error will be raised when you try to authorize access to the virtual chunk data. Again this is for security reasons.
The authorize_virtual_chunk_access kwarg maps the virtual chunk container prefix expressing the location of the virtual chunk data (e.g. s3://my-bucket/legacy/) to the bucket config you set up for that storage location.
For example authorize_virtual_chunk_access={"s3://my-bucket/legacy/": "netcdf-data"},
where "netcdf-data" is the nickname of a BucketConfig for a bucket containing some netCDF files, which are all inside the legacy/ bucket prefix.
Viewing Virtual Chunk Containers
Once set, you can view the authorized virtual chunk containers either through the web app or by using the python client.
- Web App
- Python
- Python (asyncio)
In the web app, navigate to the repository's Settings > General page. If the repository has virtual chunk containers configured, you will see a Virtual Chunk Buckets section below the Repo Bucket section.
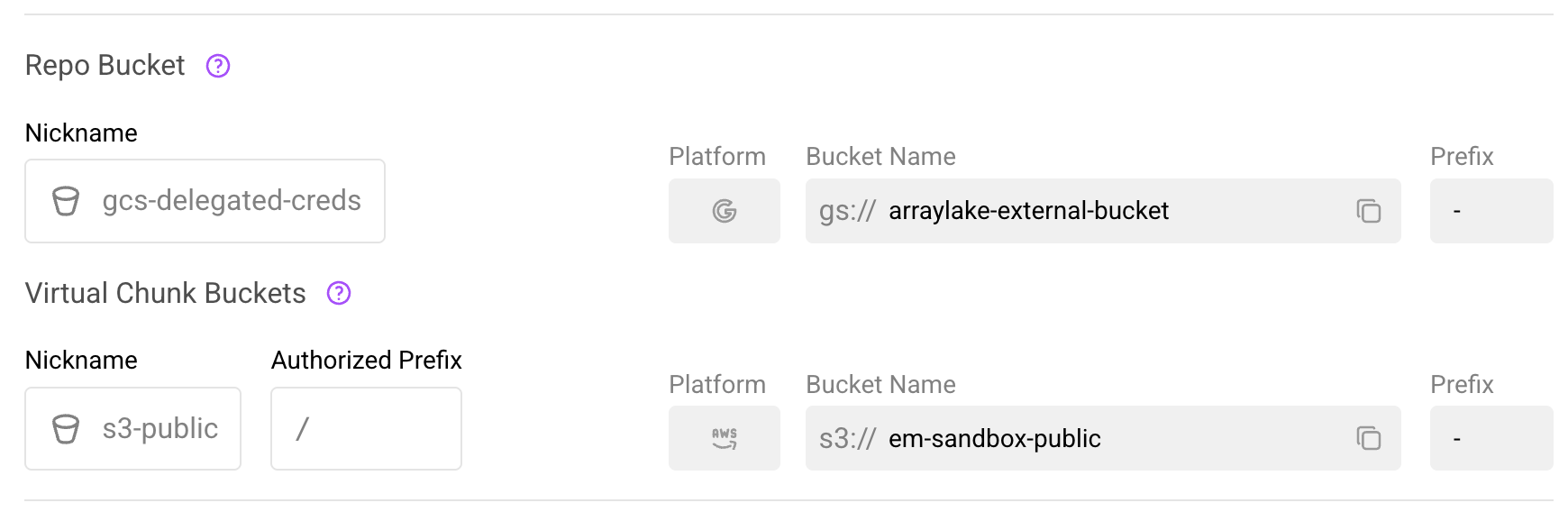
The Virtual Chunk Buckets section in repository settings.
This section displays:
- Nickname: The bucket configuration nickname
- Authorized Prefix: The path within the bucket that is authorized for virtual chunk access
- Platform, Bucket Name, Prefix: Details of the underlying bucket configuration
from arraylake import Client
client = Client()
# Get virtual chunk containers for a repo
vcc_mapping = client.get_virtual_chunk_containers("earthmover/my-repo")
print(vcc_mapping)
{'s3://noaa-gefs-retrospective/GEFSv12/reforecast/': 'noaa-gefs'}
from arraylake import AsyncClient
aclient = AsyncClient()
# Get virtual chunk containers for a repo
vcc_mapping = await aclient.get_virtual_chunk_containers("earthmover/my-repo")
print(vcc_mapping)
{'s3://noaa-gefs-retrospective/GEFSv12/reforecast/': 'noaa-gefs'}
Updating Virtual Chunk Containers
Users with write access to a repository can add or remove virtual chunk containers at any time.
- Web App
- Python
- Python (asyncio)
- Navigate to the repository's Settings > General page
- Click the Edit button (pencil icon) next to the "Virtual Chunk Buckets" heading
- To add a new virtual chunk bucket:
- Click Add Virtual Chunk Bucket
- Select a bucket from the dropdown
- Optionally specify an additional prefix path within the bucket
- The new entry will appear with a dashed border indicating it's pending
- To remove a virtual chunk bucket, click the trash icon next to the entry and confirm the removal
- Click Save Changes to apply your modifications
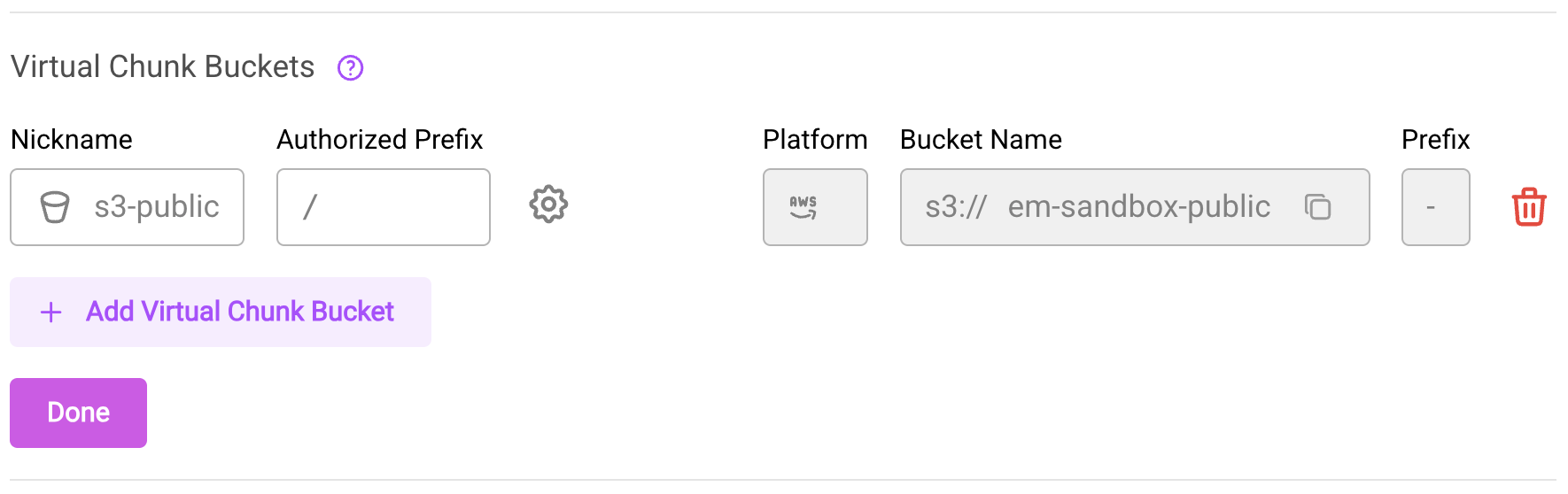
Editing the Virtual Chunk Buckets section in repository settings.
You can pass authorize_virtual_chunk_access to create_repo to set the virtual chunk containers immediately:
from arraylake import Client
client = Client()
client.create_repo(
"earthmover/my-repo",
authorize_virtual_chunk_access={"s3://another-bucket/data/": "another-bucket-config"},
)
Or use set_virtual_chunk_containers to reset the virtual chunk containers at any point later on:
from arraylake import Client
client = Client()
client.set_virtual_chunk_containers(
"earthmover/my-repo",
authorize_virtual_chunk_access={"s3://another-bucket/data/": "another-bucket-config"},
)
You can pass authorize_virtual_chunk_access to create_repo to set the virtual chunk containers immediately:
from arraylake import AsyncClient
aclient = AsyncClient()
await aclient.create_repo(
"earthmover/my-repo",
authorize_virtual_chunk_access={"s3://another-bucket/data/": "another-bucket-config"},
)
Or use set_virtual_chunk_containers to reset the virtual chunk containers at any point later on:
from arraylake import AsyncClient
aclient = AsyncClient()
await aclient.set_virtual_chunk_containers(
"earthmover/my-repo",
authorize_virtual_chunk_access={"s3://another-bucket/data/": "another-bucket-config"},
)
Virtual Chunk Access Policies
Virtual Chunk Access Policies are an org-level setting indicating that data in a specific storage location is permitted to be accessed virtually.
When you set a Virtual Chunk Access Policy, it means "I am okay with data at this storage location potentially being fetched via virtual chunk references stored in Arraylake repos". Each Virtual Chunk Access Policy is configured for a specific bucket config, and they are therefore are an Arraylake-specific concept. They can only be viewed, set, updated, or deleted by org admins.
Each Virtual Chunk Access Policy is defined by three attributes:
- The nickname of the
BucketConfigit refers to, - An optional
subprefixwithin that bucket to limit access to (e.g./all_data/public_archive/), - A boolean flag
public.
The public flag determines who can access the data within a Virtual Chunk Access Policy's subprefix.
-
"Private" Virtual Chunk Access Policies (i.e. ones with
public=False) can only ever be accessed by members of your own org.Note that the location can still potentially be accessed by any member of your own org.
-
"Public" Virtual Chunk Access Policies (i.e. ones with
public=True) can potentially be accessed by users outside of your org.This can occur if a member of your org with sufficient permissions to modify the repo either:
- Sets that repo's visibility to public, allowing any user of Arraylake to fetch the virtual chunks, or
- Creates a marketplace listing for that repo, allowing any subscriber to that listing to fetch the virtual chunks. (The user still needs to have permissions to create the subscription and read from the subscriber repo though.)
A "public" Virtual Chunk Access Policy does not make your BucketConfig public,
in the sense that another organisation wishing to create a repo that reads from the same storage location must still create their own Bucket Config to do so.
Creating such a Bucket Config requires the other org to have authority to grant read permissions to that storage location.
Bucket Configs therefore remain an org-specific entity, even if in some scenarios (described above) cross-org reading is permitted.
Viewing Virtual Chunk Access Policies
Org admins can view the Virtual Chunk Access Policies for their org via the web app or the python client.
- Web App
- Python
- Python (asyncio)
In the web app, navigate to your organization's Settings page and click the Virtual Chunks tab. This page displays all configured Virtual Chunk Access Policies for the org.
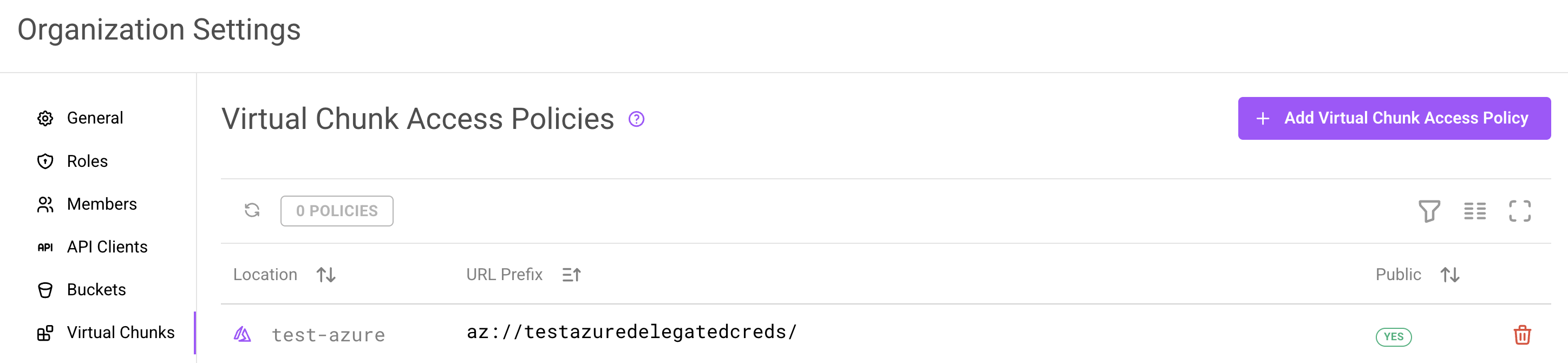
The Virtual Chunk Access Policies page in organization settings.
Each policy shows:
- Location: The bucket config (with platform icon and region)
- URL Prefix: The full storage prefix authorized for virtual chunk access
- Public: Whether the policy allows cross-org access
from arraylake import Client
client = Client()
client.list_virtual_chunk_access_policies(
org="earthmover",
)
from arraylake import AsyncClient
aclient = AsyncClient()
await aclient.list_virtual_chunk_access_policies(
org="earthmover",
)
Updating Virtual Chunk Access Policies
You can use the web app or the python client to set, overwrite, or delete Virtual Chunk Access Policies.
- Web App
- Python
- Python (asyncio)
- Navigate to your organization's Settings > Virtual Chunks page
- Click Add Virtual Chunk Access Policy in the top right
- In the modal, configure:
- Bucket: Select a bucket config from the dropdown
- Subprefix: Optionally restrict access to a path within the bucket (e.g.
public_archive/) - Visibility: Choose Private (org members only) or Public (allows cross-org access)
- Click Add to save the policy
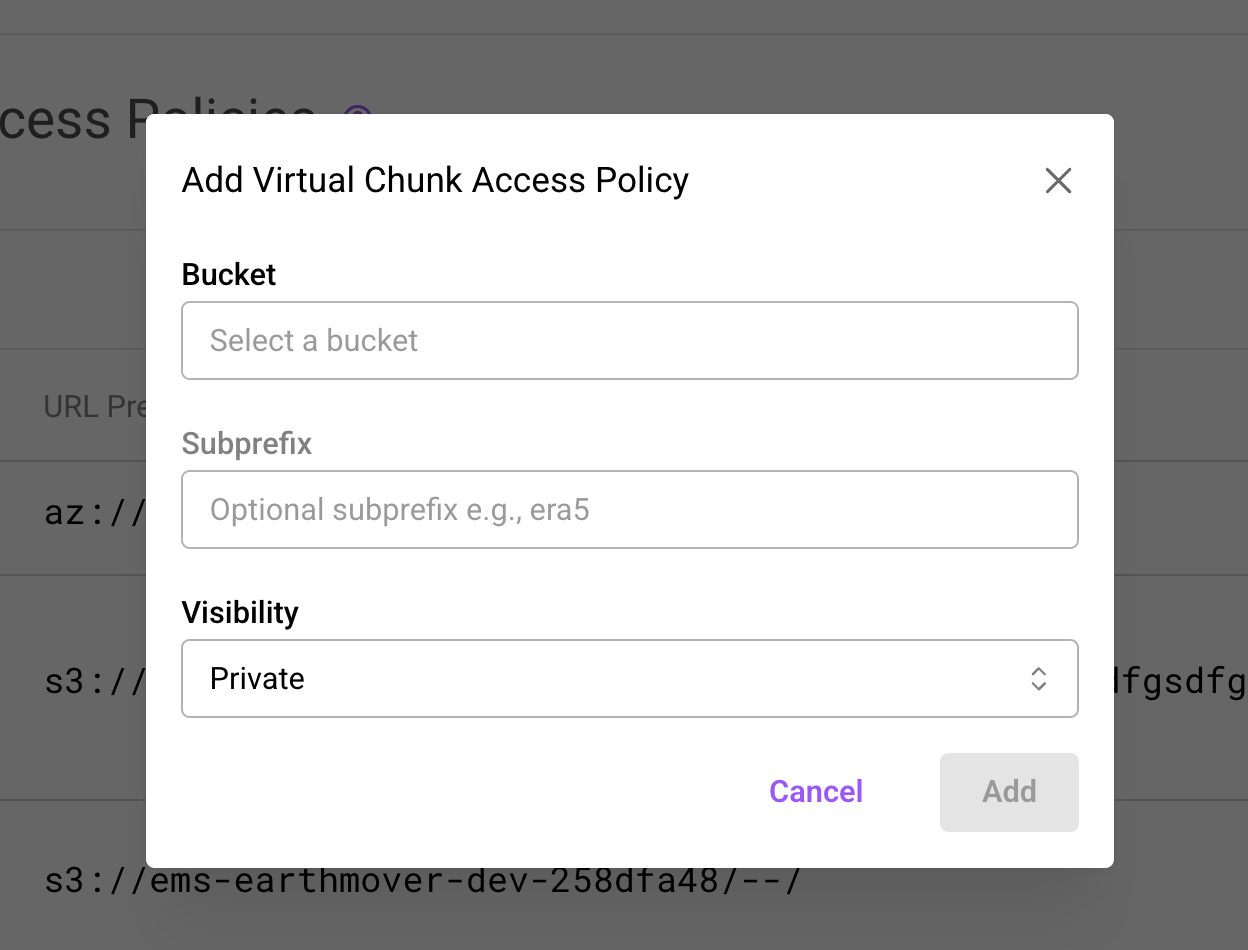
Adding a new Virtual Chunk Access Policy via the org settings modal.
To remove a policy, click the delete icon on its row and confirm the removal.
To set or to overwrite a Virtual Chunk Access Policy use client.set_virtual_chunk_access_policy.
from arraylake import Client
client = Client()
client.set_virtual_chunk_access_policy(
org="earthmover",
bucket_nickname="another-bucket-config",
subprefix="somesubprefix",
public=True,
)
To delete one use client.delete_virtual_chunk_access_policy.
from arraylake import Client
client = Client()
client.delete_virtual_chunk_access_policy(
org="earthmover",
bucket_nickname="another-bucket-config",
subprefix="somesubprefix",
public=True,
)
For deletion all three attributes have to match: bucket_nickname, subprefix, and public.
To set or to overwrite a Virtual Chunk Access Policy use aclient.set_virtual_chunk_access_policy.
from arraylake import AsyncClient
aclient = AsyncClient()
await aclient.set_virtual_chunk_access_policy(
org="earthmover",
bucket_nickname="another-bucket-config",
subprefix="somesubprefix",
public=True,
)
To delete one use aclient.delete_virtual_chunk_access_policy.
from arraylake import AsyncClient
aclient = AsyncClient()
await aclient.delete_virtual_chunk_access_policy(
org="earthmover",
bucket_nickname="another-bucket-config",
subprefix="somesubprefix",
public=True,
)
For deletion all three attributes have to match: bucket_nickname, subprefix, and public.
Ingesting Virtual Data
Let's walk through an example of ingesting some data into Arraylake as virtual chunks. We will create a mirror of the NOAA GEFS Re-forecast data available on the AWS Open Data Registry.
This involves ingesting some netCDF4 data in a public anonymous access bucket, and using the VirtualiZarr package to parse the contents of the files.
Create Bucket Config
First we need create a bucket config for the location of the data we wish to ingest. We can do this via the web app or via the python client, but here we'll use the python client:
from arraylake import Client
client = Client()
client.create_bucket_config(
org="earthmover",
nickname="noaa-gefs",
uri="s3://noaa-gefs-retrospective/",
extra_config={'region_name': 'us-east-1', 'prefix':"GEFSv12/reforecast"},
)
Set Virtual Chunk Access Policy
Now an org admin needs to permit reading from this storage by setting a Virtual Chunk Access Policy. This can be done via the web app (see Updating Virtual Chunk Access Policies above) or via the python client:
client.set_virtual_chunk_access_policy(
org="earthmover",
bucket_nickname="noaa-gefs",
subprefix="",
public=True,
)
Notice that since our bucket config already specifies prefix="GEFSv12/reforecast",
our virtual chunk access policy is already limited to that prefix, even without us narrowing further by passing subprefix.
Create Repo, with Virtual Chunk Container
Now we need to create an Arraylake repo, and authorize the virtual chunk container.
ic_repo = client.create_repo(
"earthmover/gefs-mirror",
description="NOAA data!",
metadata={"type": ["weather"]},
authorize_virtual_chunk_access={
"s3://noaa-gefs-retrospective/GEFSv12/reforecast/": "noaa-gefs",
}
)
(Recall that "s3://noaa-gefs-retrospective/GEFSv12/reforecast/" is the bucket prefix to which we want to authorize access,
and noaa-gefs is the nickname of the bucket config we set up for that bucket.)
Create virtual references and commit them to Icechunk
We use the VirtualiZarr package to parse the netCDF file and commit the virtual references to Icechunk.
VirtualiZarr needs to read the source file to build the chunk manifest, which it does through an obstore ObjectStore registered against the source bucket's URL prefix. Rather than constructing one by hand, ask the Arraylake client for a store scoped to the bucket config you set up above. This requires installing the optional obstore extra: pip install 'arraylake[obstore]'.
from virtualizarr import open_virtual_dataset
from virtualizarr.parsers import HDFParser
from obspec_utils.registry import ObjectStoreRegistry
bucket = client.get_bucket_config(org="earthmover", nickname="noaa-gefs")
# Get a read-only obstore ObjectStore for the bucket config we created.
obj_store = client.get_obstore_for_bucket(org="earthmover", nickname="noaa-gefs")
registry = ObjectStoreRegistry({bucket.url: obj_store})
session = ic_repo.writable_session("main")
url = f"{bucket.url}<path-to-file>.nc"
vds = open_virtual_dataset(url=url, parser=HDFParser(), registry=registry)
vds.vz.to_icechunk(session.store)
session.commit("wrote some virtual references!")
Read the data back
Finally, we can now access the data we ingested!
Notice users do not need to authorize at read-time by passing authorize_virtual_chunk_access, though if they want to override by passing it they can.
import xarray as xr
ic_repo = client.get_repo(
"earthmover/gefs-mirror",
)
session = ic_repo.readonly_session("main")
ds = xr.open_zarr(session.store)
ds["some_variable"].plot()
Advanced ingestion
More complicated virtual data ingestion tasks are possible, including:
- Concatenating references to multiple files before ingestion,
- Appending to existing datasets along a specific dimension (e.g.
time), - Ingesting other data formats.
For information about such workflows, please see the Icechunk documentation on Virtual Datasets and the VirtualiZarr documentation.